今天给大家分享住哪儿网(www.zhuna.cn)酒店基本信息采集规则。
今天为大家讲解网址拼接,我们经常在采集的时候,发现源码中并没有完全的网址或完全的网站不好制定规则,那就可以使用网址拼接。
下方案例讲解为大家详细说明。
本规则为火车采集器V9版规则,其他低版本不可使用。
本规则采集住哪儿网酒店基本信息,本规则仅供学习参考,仅抓取北京地区的酒店为例。
本规则免费版用户可使用
本规则仅供广大用户学习交流参考,不可用以违法目的或商业用途,我们不对因使用此规则造成的任何法律问题承担责任。
商业版用户有问题或付费定制规则请联系官方客服QQ:800019423 服务热线:400-8757-060 火车采集器V9酒店信息采集规则分享.rar
火车采集器V9酒店信息采集规则分享.rar
欢迎关注官方微信公众号,及时了解最新信息

【案例讲解】
今天主要讲下网址拼接,其他略过!
以北京地区酒店信息为例,入口页面:http://www.zhuna.cn/hotellist/e0101/
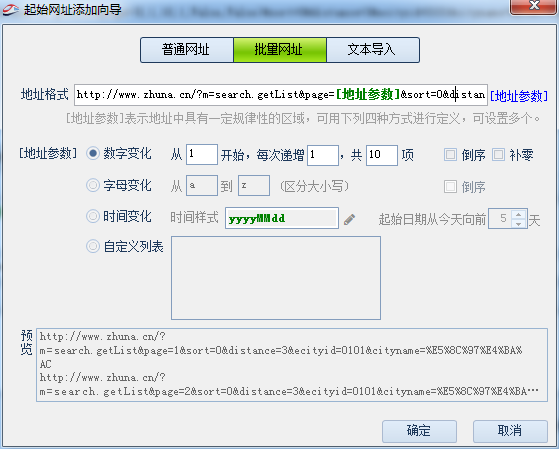
通过页面点击发现这并不是真实的数据列表页,需要通过抓包软件来抓包,找出真实列表网址(抓包之前说过,今天这里不再细说),通过抓包获得真实网址为:http://www.zhuna.cn/?m=search.ge ... =%E5%8C%97%E4%BA%AC
网址中的page=1为列表页分页参数,通过分页规则,采集列表网址,如图:
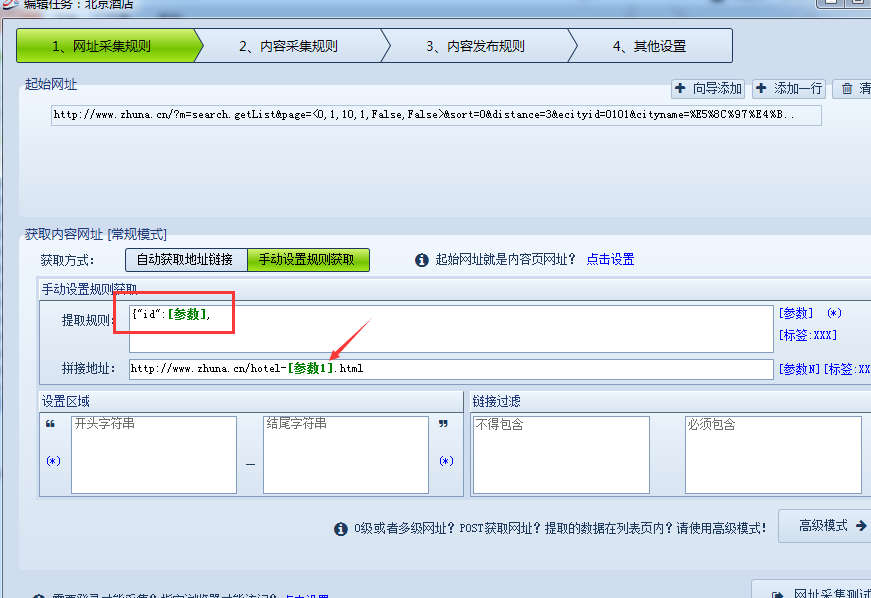
下一步获取内容页网址,通过源码分析,发现源码中并没有网址,但可以看到一个ID值,如图:

通过页面点击内容页发现内容网址为http://www.zhuna.cn/hotel-5396.html 网址中的数字很可能就是这个ID值,将源码中的ID值替换到这个网址中,发现就是酒店详细内容页,这样我们只要采集这个ID值即可。这个获取规则也很简单,以{"id":开头,以 , 结尾,就可以获取到ID值,但光有ID值不行,这个时候我们要拼接出完整的内容网址,那这样拼接http://www.zhuna.cn/hotel-[参数1].html即可,如图:
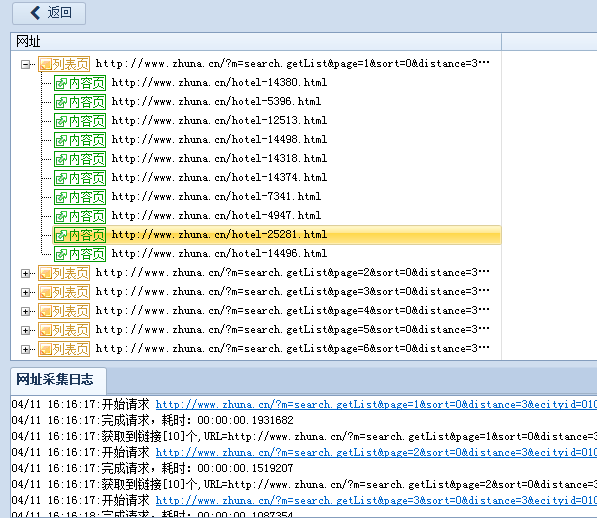
通过网址测试,可以顺利采集到内容网址
酒店的基本信息在内容页源码中都有,规则也比较简单,在这里就略过,最后来张采集动态图
很帅吧,赶紧下载规则学习,你也可以的哦!
联系我们
客服QQ:800019423
客服电话:400-8757-060
软件购买:http://www.locoy.com/buy