苹果举办了Apple 2018秋季发布会
史上最贵的iPhone横空出世
售价高达12799元!
吓得小采
赶紧摸了摸肾还在不?

其实么,有时候做个吃瓜群众挺好的
说到吃瓜群众就不得不谈谈大知了
今天我们就来探讨一下
如何采集知乎群众对“iPhone”的看法吧!

1
第一步:在浏览器中打开知乎网站,然后登录知乎账号,登录后打开fiddler用于抓包,做好上述准备工作后。搜索你感兴趣的关键词,这次我们使用‘iphone’ 作为关键词,fiddler进行抓包。因为知乎是瀑布流形式的下一页,因此,我们再往下拖动瀑布流,抓取更多页的列表页。
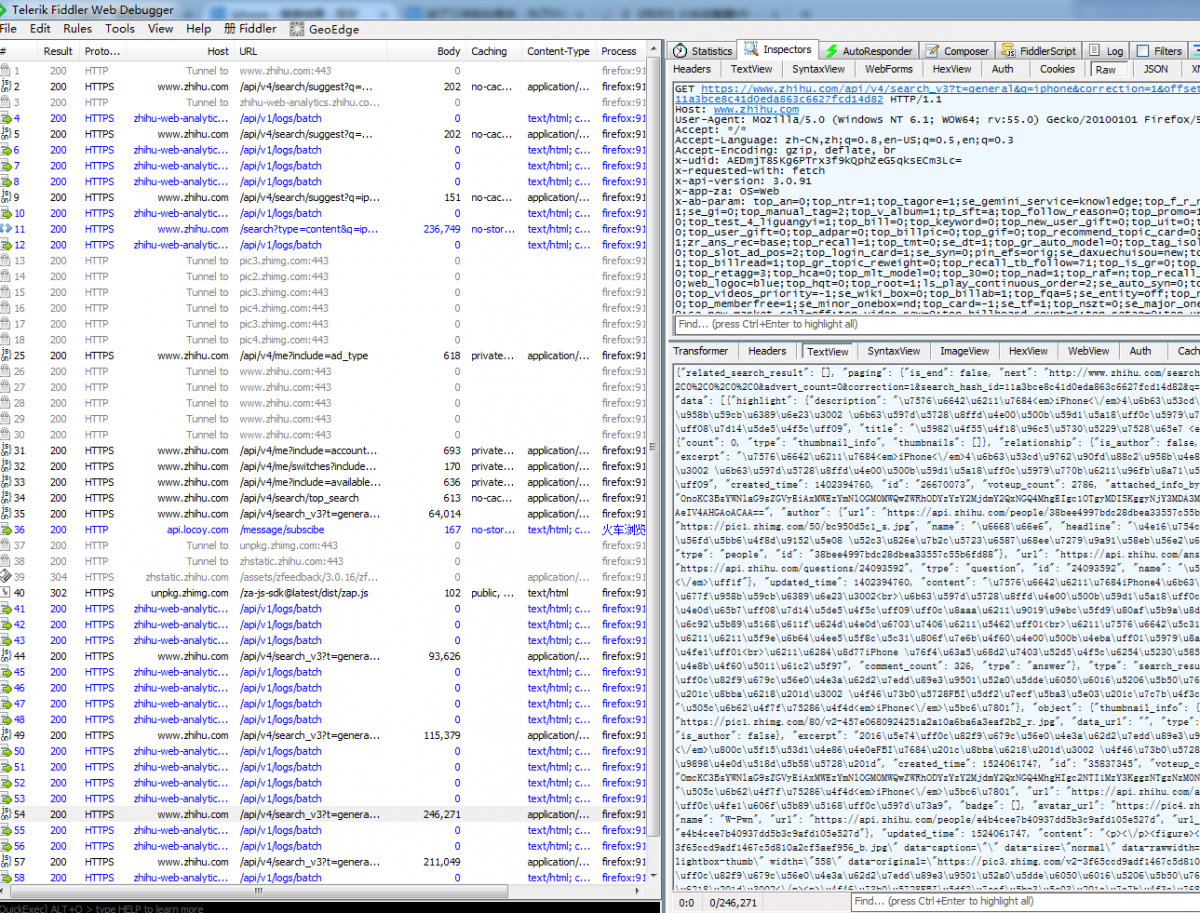
抓取数据如上图
2
第二步:接下来我们要分析,列表页地址在哪一个请求里面,找第一页的网址,然后在fiddler中进行搜索。找到包含地址的网址,然后记录下来。接下来找第二页中的网址,然后在fiddler中分析,
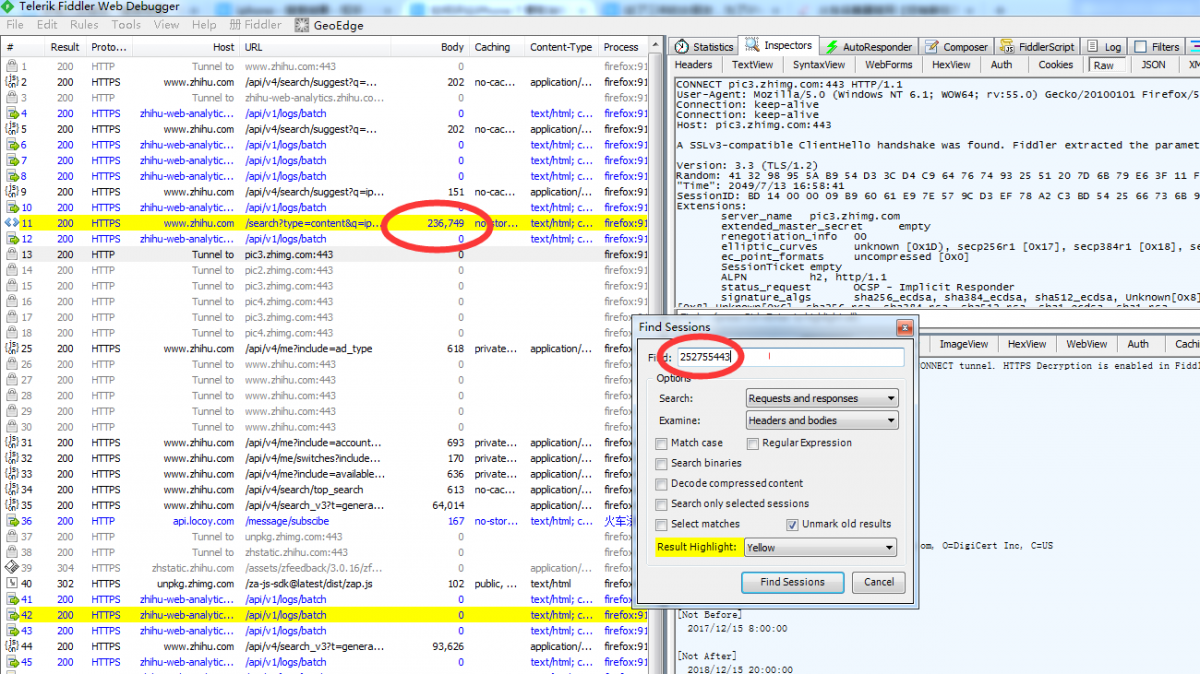
可以看到我记录的网址分布规律:

第一页地址,跟第二页第三页的格式分配规律不同,然后分析可以看到第二页第三页中变化的参数是offset,我们改变offset的值为零,可以看到源码中是有第一页中的内容的,所以我们用这个地址作为第一页的地址,然后再分析内容页地址。
知乎有两种类型的网页,我们取这种类型的网页:
通过分析源码得到列表页提取规则如下:
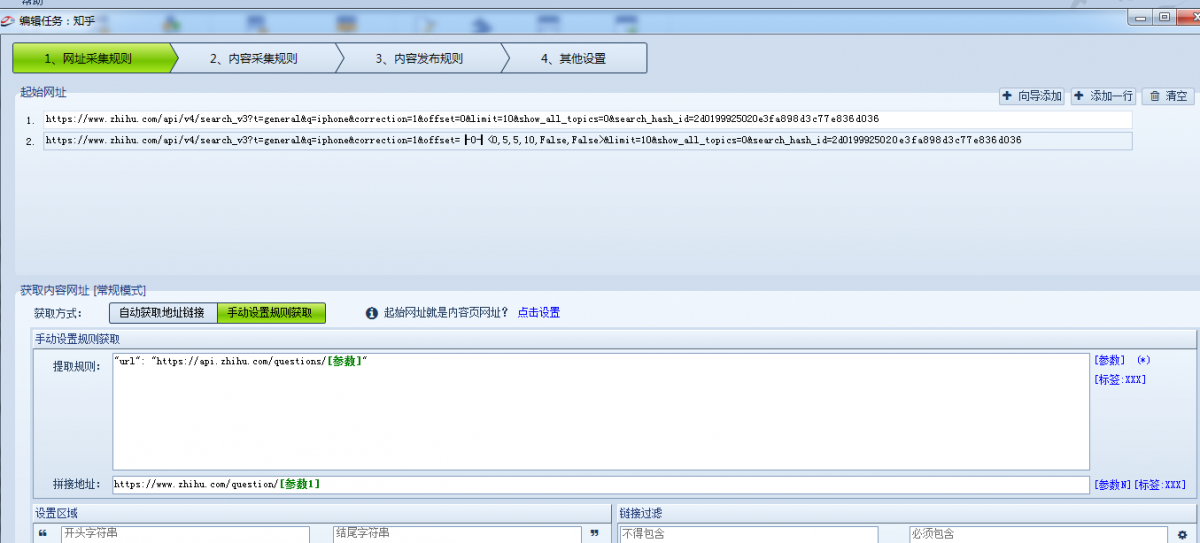
3
第三步:在内容页源码中找所需字段的前后代码,以内容字段的前后分析字段示例:
采集页面:
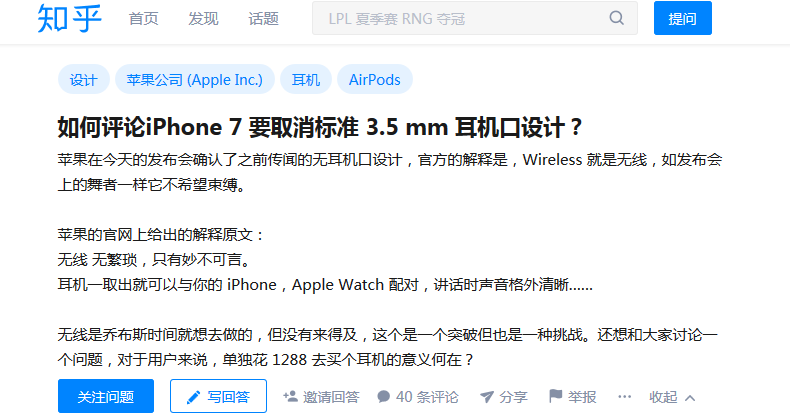
源码示例:

采集器设置:

其余字段分析原理一致,不做赘述。
采集结果如下:
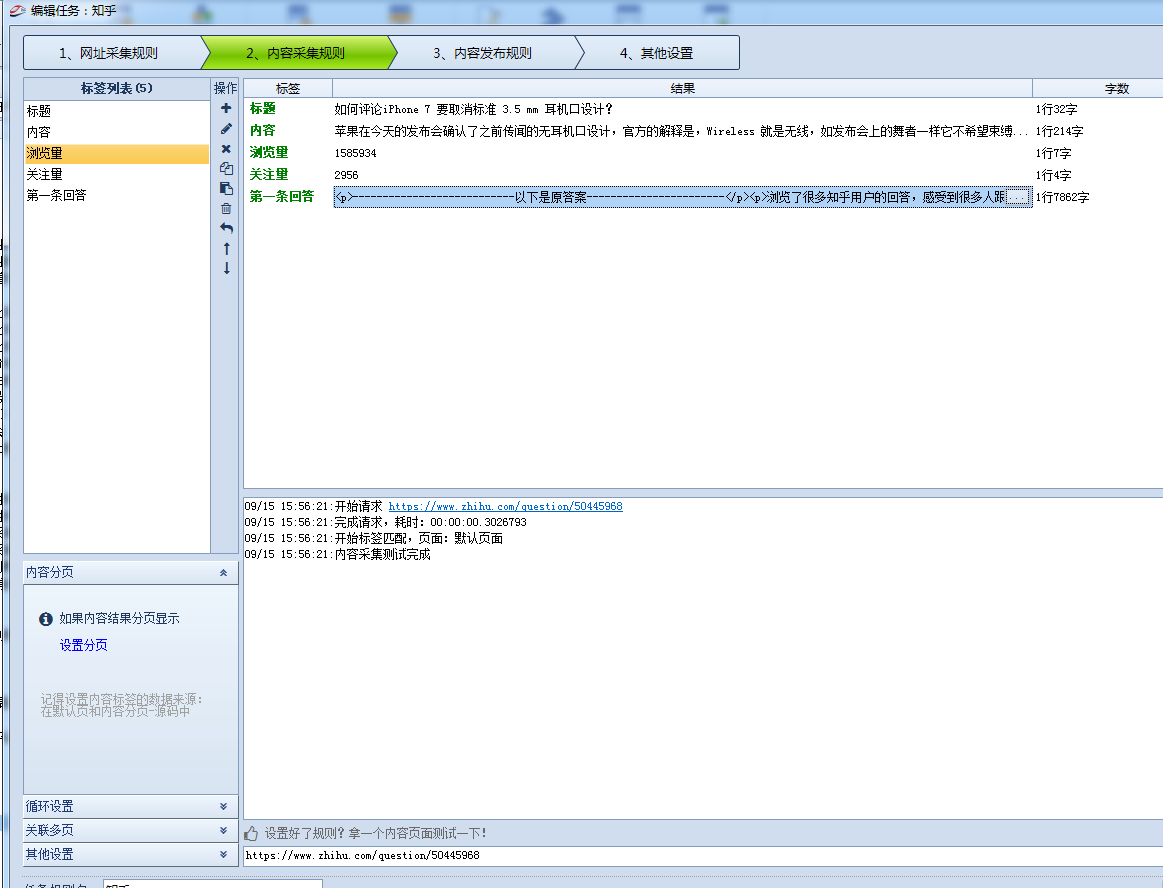
此次编写需注意:
1. fiddler的熟练使用,可以参考教程:http://faq.locoy.com/q-1129.html
联系我们
客服QQ:800019423
客服电话:400-8757-060